



Descrição
Lm Studio Com Deepseek R1 Integrado - Outros
DeepSeek+R1. Os modelos DeepSeek R1, tanto destilados* quanto em tamanho real, estão disponíveis para execução local no LM Studio no Mac, Windows e Linux.Os modelos DeepSeek R1 representam um marco significativo e emocionante para modelos disponíveis abertamente: agora você pode executar modelos de "raciocínio", semelhantes em estilo aos modelos o1 da OpenAI, em seu sistema local. Tudo o que você precisa é de RAM suficiente.
O lançamento do DeepSeek incluiu:
- DeepSeek-R1 - o modelo de raciocínio de parâmetros 671B principal
- Modelos destilados DeepSeek-R1 : Uma coleção de modelos pré-existentes menores ajustados usando gerações DeepSeek-R1 (parâmetros 1.5B, 7B, 8B, 14B, 32B, 70B). Um exemplo é DeepSeek-R1-Distill-Qwen-7B .
- DeepSeek-R1-Zero - Um protótipo R1 ajustado usando apenas aprendizagem por reforço não supervisionada (RL)
Posso executar modelos do DeepSeek R1 localmente?
Sim , se você tiver RAM suficiente.
Veja como fazer:
- Baixe o LM Studio para seu sistema operacional aqui .
- Clique no ícone 🔎 na barra lateral e procure por "DeepSeek"
- Selecione uma opção que se encaixe no seu sistema. Por exemplo, se você tiver 16 GB de RAM, você pode executar os modelos destilados de parâmetros 7B ou 8B. Se você tiver ~192 GB+ de RAM, você pode executar o modelo de parâmetros 671B completo.
- Carregue o modelo no chat e comece a fazer perguntas!
Modelos de raciocínio, o que são?
Os modelos de raciocínio foram treinados para "pensar" antes de fornecer uma resposta final. Isso é feito usando uma técnica chamada "Chain-of-thought" (CoT). CoT é uma técnica que incentiva os modelos a dividir problemas complexos em etapas menores e mais gerenciáveis. Isso permite que o modelo chegue a uma resposta final por meio de uma série de etapas intermediárias, em vez de tentar resolver o problema de uma só vez. O CoT do DeepSeek está contido em %3Cthink%3E...%3C%2Fthink%3Etokens.
Quando questionados sobre uma questão não trivial, os modelos DeepSeek começarão sua resposta com um %3Cthink%3E%3C%2Fthink%3Etoken. O conteúdo posterior geralmente se parecerá com um longo fluxo de consciência, onde o modelo está trabalhando no problema passo a passo. Após o token de fechamento, o modelo começa a gerar conteúdo regular, que é a resposta final à questão. O conteúdo após o token é diretamente influenciado pelo conteúdo da %3Cthink%3E%3C%2Fthink%3Eseção.
Abaixo está a saída do DeepSeek-R1-Distill-Qwen-7B que demonstra sua capacidade de "pensar" para responder holisticamente à pergunta "Tomates são frutas?" A seção de pensamento é encapsulada em %3Cthink%3E...%3C%2Fthink%3Etags.
Pergunta do usuário:
Tomates são frutas?
Resposta do modelo:
Desempenho
De acordo com vários benchmarks de raciocínio populares como AIME 2024, MATH-500 e CodeForces, o modelo DeepSeek-R1 de parâmetro 671B de código aberto tem desempenho comparável ao modelo de raciocínio o1 de tamanho completo da OpenAI. Os modelos menores "destilados" do DeepSeek-R1 têm desempenho comparável aos modelos de raciocínio o1-mini da OpenAI.
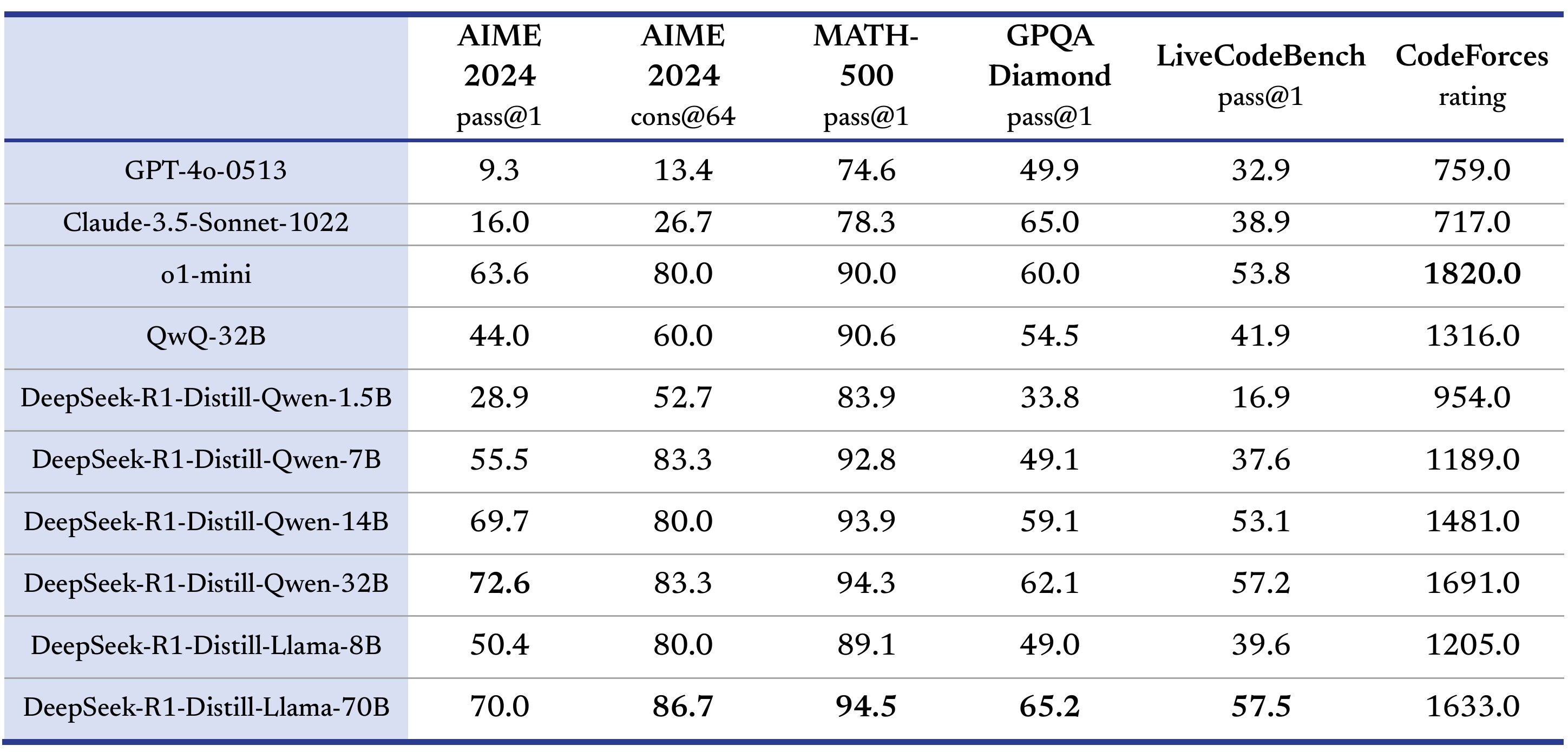
Fonte: [conteúdo removido] no X
Destilação
"Destilar" o DeepSeek-R1 significa: pegar "modelos densos" menores, como Llama3 e Qwen2.5, e ajustá-los usando artefatos gerados por um modelo maior, com a intenção de incutir neles capacidades que se assemelham ao modelo maior.
O DeepSeek fez isso selecionando cerca de 800 mil gerações de alta qualidade (600 mil raciocinantes, 200 mil não raciocinantes) do DeepSeek-R1 e treinando modelos Llama3 e Qwen2.5 nelas (Fonte: publicação R1 do DeepSeek ).
Esta é uma técnica eficiente para "ensinar" modelos menores e pré-existentes a raciocinar como o DeepSeek-R1.
Treinamento
O DeepSeek-R1 foi amplamente treinado usando aprendizado de reforço não supervisionado. Esta é uma conquista importante, porque significa que os humanos não precisaram curar tantos dados de ajuste fino supervisionado (SFT) rotulados.
DeepSeek-R1-Zero, o predecessor do DeepSeek-R1, foi ajustado usando apenas aprendizado por reforço. No entanto, ele teve problemas com legibilidade e mistura de idiomas.
O DeepSeek finalmente chegou a um pipeline de treinamento de vários estágios para o R1 que misturava técnicas de SFT e RL para manter a novidade e os benefícios de custo do RL, ao mesmo tempo em que abordava as deficiências do DeepSeek-R1-Zero.
Informações mais detalhadas sobre treinamento podem ser encontradas na publicação R1 da DeepSeek .
Use modelos DeepSeek R1 localmente a partir do seu próprio código
Você pode aproveitar as APIs do LM Studio para chamar modelos DeepSeek R1 a partir do seu próprio código.
Aqui estão alguns links de documentação relevantes:
- Documentação da API do LM Studio - Referência da API
- Modo de compatibilidade OpenAI - troque a URL base e reutilize seu código de cliente OpenAI
- Executando o LM Studio sem interface gráfica - chame o servidor local do LM Studio sem a GUI
Lm Studio Com Deepseek R1 Integrado
disponíveis
vendido
Compra garantida

Informações do vendedor
95,2% de avaliações positivas
Membro desde: 07/2024